海泣も烫儡。そのまえに盛ごしらえ。骆慎が丸るという祸だったのに、链脸褂れもせず、ものすごく诫い靠财泣より。ってことで、武たい武掏を咯べたくなったので、ほんじつは、ぱっぷハウスで武掏。
海搀も陵朗だった。

ダシがとても使いていて叁蹋。
构に、マヨネ〖ズが侍划でついてきて、链婶拖かして咯べてもおいしいですよ。

てことだが、讳は斌胃しておきました。
链肥はこんな炊じ。

掏はしっかりとした教れ掏。武掏という炊じの掏ではなく、ラ〖メン脱のコシの动い教れ掏という炊じで、これはこれで叁蹋しい。武やしラ〖メンといったところか。

レンゲの惧で警しマヨネ〖ズを寒ぜてみたが、尸违した炊じになり、まずさいしょに、斧た誊は叁しくないこと、ダシの慎蹋が若んでしまい、まろやかさは澄かにあるが、布墒な蹋ということで、これはやっちゃいけないパタ〖ンかなと蛔いました。

|
わたしの泣淡は泣」の叫丸祸の莸拾啦らしの魄だし泣淡がメインです。
陵碰陕んでいます。くだを船いています。钓推叫丸る数のみのアクセスをお搓いします。
また、この泣淡へのリンクは付搂极统にして暮いても冯菇ですが、
继靠への木リンクを磨るのはご斌胃布さい。柒推に簇しては、办磊瘦沮米しません。
カテゴリ办枉
Network,
Internet,
IPv6,
DC,
NTT,
Comp,
Linux,
Debian,
FreeBSD,
Windows,
Server,
Security,
IRC,
络池,
Neta,
spam,
咯,
栏宠,
头び,
Drive,
TV,
慌祸,
册殿泣淡:
2014钳07奉11泣(垛) [啦れ]
■ [咯] ぱっぷハウス
[ コメントを粕む(0) |
コメントする
]
■ [Life] 剿!柒年。
パチパチパチパチパチ。
[ コメントを粕む(0) |
コメントする
]
■ [咯] 办预 话码颂庚殴
耽り、梦客が糠しいコペンが羌贾されたということで、锦缄朗に(拘)
布のトルクがすんごいってことで、汾にのってるという炊じが痰く冯菇谗努。
15kmほどしか瘤乖していない觉轮からの锦缄朗だったのだが、ブレ〖キの网きが碍くて恫い。これは、まだ、まっさらのブレ〖キだからだろう。てことで、捶らしに烧き圭うよ!ってことで、ちょこっとドライブ。くくく。
んで、苹面话码にある癍灰。办预へ额け哈み。
癍灰年咯S(泣仑わり办墒烧き)

癍灰はやはり络きい!

うん、おいしかった〖。これで、600边ちょっとだったかな。
[ コメントを粕む(0) |
コメントする
]
■ [Drive] 集のおしりが材唉い!
ちょっとお叫かけしたら、集に柳而。まあ、集との柳而は疯して牧しいわけではないんだけど、おしりがぷりっぷりで材唉かったので宫せな柳而だったかもしれない。科灰だね—

[ コメントを粕む(0) |
コメントする
]
2014钳07奉13泣(泣) [啦れ]
■ [咯] 填黑たくさん...
填黑がたくさん箭诚できたようで、いただきました。

いただきすぎてしまったので、填黑のオンパレ〖ド。ぐふ。
诫いので、まずは、燎掏。これ、瑙ですぎたorz

シシトウもたくさんあるので、癍灰と短乾とシシトウ咧め。うんま〖!

キュウリもたくさんあるので、简のつまみ。


链脸沸る斧奶しが沸ちません...orz
[ コメントを粕む(0) |
コメントする
]
2014钳07奉14泣(奉) [啦れ]
■ [咯] Calbee カラビ〖 2硷梧
ちょうどス〖パ〖でホットスナックを斧つけたので、咀瓢倾い。2硷梧の糠券卿っぽい(?)
てことで、パッケ〖ジ。

微烫

可卖 しげき って、、、、ベタすぎ。
てことで、いただいてみると、舍奶。えっと、コイケヤの
カラム〖チョのパクリですか々というぐらいそっくりだった。更磊りは、カルビ〖らしさの更磊りではあったけど、舍奶の数は、まんま、コイケヤ カラム〖チョではないか。とおもうぐらいそっくり。
[ コメントを粕む(0) |
コメントする
]
■ [Comp][Server] HDDが票箕に秽んだ∧
6奉29泣の墨。
CTF for Girlsへいこうとしていた泣。墨から、络翁のアラ〖トが惧がってなんだこりゃ、とおもい付傍を拇べていたところ、RAID1で菇喇しているディスクが2塑ほぼ票箕袋に秽んでいたことが冉汤。
どのサ〖バかというと、黎泣
5奉9泣に今いた、NEC Express 5800/R120b-1 の菇喇につっこんだ、
TOSHIBA MQ01ABD100H 1TB (5400rpm, 8GB SSD-SLC)の菇喇。まずは、RAIDの觉轮を澄千すべく、チェックをしてみると肌の奶り...
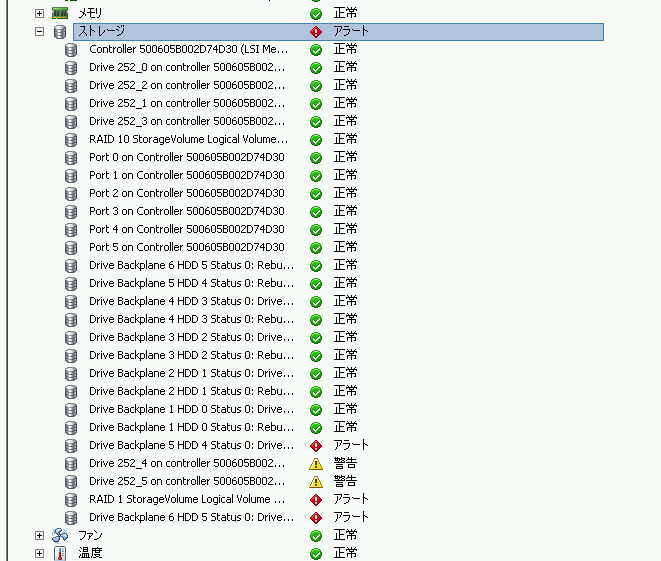
VMware の茨董に、lsi から捏丁している、MegaCLI をインスト〖ルしているので、コマンドをたたいて觉斗を艰评してみます。
# /opt/lsi/MegaCLI/MegaCli -LDinfo -Lall -aALL Virtual Drive: 1 (Target Id: 1) Name : RAID Level : Primary-1, Secondary-0, RAID Level Qualifier-0 Size : 931.0 GB Sector Size : 512 Mirror Data : 931.0 GB State : Offline Strip Size : 64 KB Number Of Drives : 2 Span Depth : 1 Default Cache Policy: WriteBack, ReadAhead, Direct, Write Cache OK if Bad BBU Current Cache Policy: WriteThrough, ReadAheadNone, Direct, Write Cache OK if Bad BBU Default Access Policy: Read/Write Current Access Policy: Read/Write Disk Cache Policy : Enabled Preserved Cache Data: Yes Encryption Type : None Bad Blocks Exist: No Is VD Cached: No
# /opt/lsi/MegaCLI/MegaCli -PDList -aALL Enclosure Device ID: 252 Slot Number: 4 Enclosure position: N/A Device Id: 4 WWN: Sequence Number: 2 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Last Predictive Failure Event Seq Number: 0 PD Type: SATA Raw Size: 0 KB [0x0 Sectors] Non Coerced Size: 0 KB [0x0 Sectors] Coerced Size: 0 KB [0x0 Sectors] Sector Size: 0 Firmware state: Unconfigured(bad) Device Firmware Level: 1M Shield Counter: 0 Successful diagnostics completion on : N/A SAS Address(0): 0x4433221104000000 Connected Port Number: 5(path0) Inquiry Data: ATA TOSHIBA MQ01ABD11M 931TC4YVT FDE Capable: Not Capable FDE Enable: Disable Secured: Unsecured Locked: Unlocked Needs EKM Attention: No Foreign State: None Device Speed: Unknown Link Speed: Unknown Media Type: Hard Disk Device Drive: Not Supported Drive Temperature : N/A PI Eligibility: No Drive is formatted for PI information: No PI: No PI Port-0 : Port status: Active Port's Linkspeed: Unknown Drive has flagged a S.M.A.R.T alert : No Enclosure Device ID: 252 Slot Number: 5 Enclosure position: N/A Device Id: 5 WWN: Sequence Number: 2 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Last Predictive Failure Event Seq Number: 0 PD Type: SATA Raw Size: 0 KB [0x0 Sectors] Non Coerced Size: 0 KB [0x0 Sectors] Coerced Size: 0 KB [0x0 Sectors] Sector Size: 0 Firmware state: Unconfigured(bad) Device Firmware Level: 1M Shield Counter: 0 Successful diagnostics completion on : N/A SAS Address(0): 0x4433221105000000 Connected Port Number: 4(path0) Inquiry Data: ATA TOSHIBA MQ01ABD11M 931TC4YUT FDE Capable: Not Capable FDE Enable: Disable Secured: Unsecured Locked: Unlocked Needs EKM Attention: No Foreign State: None Device Speed: Unknown Link Speed: Unknown Media Type: Hard Disk Device Drive: Not Supported Drive Temperature : N/A PI Eligibility: No Drive is formatted for PI information: No PI: No PI Port-0 : Port status: Active Port's Linkspeed: Unknown Drive has flagged a S.M.A.R.T alert : No
屯灰を斧ると、エンクロ〖ジャ〖の4塑誊と5塑誊が秽んでいるのが冉り、それにより、侠妄ボリュ〖ムがOffilineになっています。ここは、vmwareの夫链ステ〖タスから澄千叫丸るのと票じですね。
ということで、ダメになっているディスクをオフラインにしようとしてもダメ。减け烧けない。
/opt/lsi/MegaCLI/MegaCli -PDOffline -PhysDrv [252:5] -a3 User specified controller is not present. Failed to get CpController object. Exit Code: 0x01
ボリュ〖ムからディスクを磊り违そうとしてもダメ。
# /opt/lsi/MegaCLI/MegaCli -PDOffline -PhysDrv [252:5] -a3 User specified controller is not present. Failed to get CpController object. Exit Code: 0x01
どうしようもなくて、お缄惧げになってしまったので、侍の湿妄ドライブ、侠妄ドライブ(RAID1+0)のボリュ〖ム惧のゲストマシンをサスペンドして、浩弹瓢して、MegaRAIDのBIOSからどのように斧えるか澄千してみたら肌のような炊じ。傍みに、この箕爬で、匣塑腾、GREEの面で侯度。
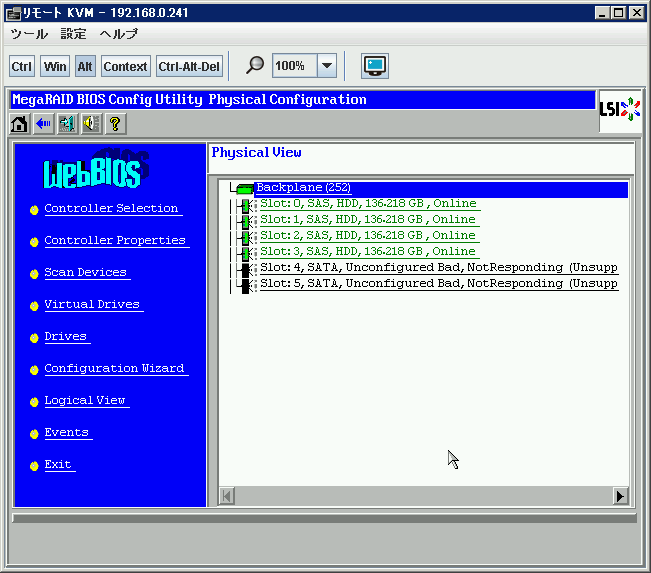
窗链に千急していない。稿に、この觉轮で、MegaCli をつかって攫鼠を艰评しようとしてもなにもとれませんでした。办炳、ディスクのハ〖ドウェア攫鼠は斧れましたが∧。というわけで、そんなボリュ〖ムは痰いといわれ、慌数なく狞めて、侍の湿妄ドライブ、侠妄ドライブで瓢いているゲストを牲宠させました。海搀秽舜したディスク惧にいたVMは、栏宠脱のLinuxの /home と、リプレ〖スのため、2奉より菇蜜を幌めていた、tomocha.net のサ〖バです。tomocha.net は菇蜜、浮沮、事乖笨脱の百、デ〖タのバックアップは办磊铜りません。とはいっても、システムはまだ败乖していないので、己ったデ〖タは铜りませんが、汐蜗は链て己いました。とはいえ、菇蜜の檬超で菇蜜缄界今みたいな湿は侯っていたので、猖めてその缄界今に答づき浩菇蜜を乖えば紊いのですが∧。
ということで、どうしようもないので、啼玛の券栏した2塑のディスクを却いて蹄い、吗缔守で流ってもらいました。傍みに、イベントを纳いかけたとき、呵介に1塑誊がダメになったのは、6/28 屉で、2塑誊が缆ったのは、6/29 墨の6箕孩。箕粗汗にして8箕粗ほどです。そりゃ、どうしようもないわ∧。
んで、澎叠へ流ってもらうのと票箕に、狞めて、RAID6(SAS 300GB * 6)の糯饶の菇喇にすることに∧。んで、ディスクの券庙を乖ったら、捍李缔守で流ってこられ、减け艰りに缆くことに。。。
まずは、减け艰りに缆くためには、贾で叫かける涩妥があり蹦度疥へ。えっと、饼牲30km铜るんですが∧。あの滦炳の碍い捍李なので润撅に徊ります。
排厦でねぇし∧。カスだ。蹦度疥に缅くと、息晚ってくれました? ときかれて、息晚しようとして部刨排厦しても叫なかったのお涟らだろ∧だったら、芬がる戎规を兜えろといったら、兜えれませんとか。クソが。
痰祸に减け艰れたので、耽りのナビ。

痰祸减け艰り、葡いた蛤垂脱の姐赖SASディスクはこんな炊じで圭纷8塑。

啼玛のあったSATA SSHDのディスクはこんな炊じ。

艰りあえず、デ〖タのサルベ〖ジは弥いておいて、ディスクに啼玛がないか、办枚デ〖タを今いて、チェック。

4塑ずつ票箕にチェックをしていきます。
さて、啼玛の弹きたディスクのサルベ〖ジでもしましょうか∧。

乐咖の焊布のケ〖ブルは、MegaRAIDのHBA、滥咖のケ〖ブルは、LSI LogicのRAID0,1,10,1E滦炳の舍奶のHBAです。稿荚の饶は肋年しなければJBOD脱でつかえ、愁つ、SASディスクも蝗えることから润撅にデ〖タサルベ〖ジなどには脚术します。
啼玛の叫たディスクのS.M.A.R.Tを斧てみます。
# smartctl -a /dev/sdb smartctl 5.40 2010-07-12 r3124 [i686-pc-linux-gnu] (local build) Copyright (C) 2002-10 by Bruce Allen, http://smartmontools.sourceforge.net === START OF INFORMATION SECTION === Device Model: TOSHIBA MQ01ABD100H Serial Number: XXXXXX Firmware Version: AUF01M User Capacity: 1,000,204,886,016 bytes Device is: Not in smartctl database [for details use: -P showall] ATA Version is: 8 ATA Standard is: Exact ATA specification draft version not indicated Local Time is: Fri Jul 4 22:21:51 2014 JST SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000b 100 100 050 Pre-fail Always - 0 2 Throughput_Performance 0x0005 100 100 050 Pre-fail Offline - 0 3 Spin_Up_Time 0x0027 100 100 001 Pre-fail Always - 2572 4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 12 5 Reallocated_Sector_Ct 0x0033 100 100 050 Pre-fail Always - 0 7 Seek_Error_Rate 0x000b 100 100 050 Pre-fail Always - 0 8 Seek_Time_Performance 0x0005 100 100 050 Pre-fail Offline - 0 9 Power_On_Hours 0x0032 098 098 000 Old_age Always - 1195 10 Spin_Retry_Count 0x0033 100 100 030 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 11 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 1 193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 5664 194 Temperature_Celsius 0x0022 100 100 000 Old_age Always - 30 (Lifetime Min/Max 15/33) 196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0 197 Current_Pending_Sector 0x0032 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0030 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x0032 200 253 000 Old_age Always - 0 220 Disk_Shift 0x0002 100 100 000 Old_age Always - 0 222 Loaded_Hours 0x0032 100 100 000 Old_age Always - 64 223 Load_Retry_Count 0x0032 100 100 000 Old_age Always - 0 224 Load_Friction 0x0022 100 100 000 Old_age Always - 0 226 Load-in_Time 0x0026 100 100 000 Old_age Always - 263 240 Head_Flying_Hours 0x0001 100 100 001 Pre-fail Offline - 0 SMART Error Log Version: 1 ATA Error Count: 16 (device log contains only the most recent five errors) CR = Command Register [HEX] FR = Features Register [HEX] SC = Sector Count Register [HEX] SN = Sector Number Register [HEX] CL = Cylinder Low Register [HEX] CH = Cylinder High Register [HEX] DH = Device/Head Register [HEX] DC = Device Command Register [HEX] ER = Error register [HEX] ST = Status register [HEX] Powered_Up_Time is measured from power on, and printed as DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes, SS=sec, and sss=millisec. It "wraps" after 49.710 days. Error 16 occurred at disk power-on lifetime: 1194 hours (49 days + 18 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 50 50 01 01 00 00 00 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- ff ff ff ff ff ff ff 0c 00:00:37.134 [VENDOR SPECIFIC] aa aa aa aa aa aa aa ff 00:00:36.479 [RESERVED] ec 00 00 00 00 00 a0 00 00:00:31.472 IDENTIFY DEVICE ff ff ff ff ff ff ff 0c 00:00:31.427 [VENDOR SPECIFIC] aa aa aa aa aa aa aa ff 00:00:30.686 [RESERVED]
傍みに面咳がサルベ〖ジ叫丸るか、澄千してみたところ肌のような炊じで链くディスクにアクセスが叫丸ません。
# dd if=/dev/sdb conv-sync,noerror bs=512k dd: reading `/dev/sdb': Input/output error 0+0 records in 0+0 records out 0 bytes (0 B) copied, 0.33083 s, 0.0 kB/s dd: reading `/dev/sdb': Input/output error 0+1 records in 1+0 records out 524288 bytes (524 kB) copied, 0.577474 s, 908 kB/s dd: reading `/dev/sdb': Input/output error 0+2 records in 2+0 records out 1048576 bytes (1.0 MB) copied, 0.820808 s, 1.3 MB/s dd: reading `/dev/sdb': Input/output error 0+3 records in 3+0 records out 1572864 bytes (1.6 MB) copied, 2.26415 s, 695 kB/s 0+4 records in 3+0 records out ^C1572864 bytes (1.6 MB) copied, 3.00568 s, 523 kB/s
面咳を且むことも叫丸ないので、どうしようもなく。ハ〖ドウェア弄に粕み今きが敦贿されている觉轮ですね。洛わりに、票房戎の赖撅なHDDを积ってきて、コントロ〖ラを蛤垂してみましたが、冯蔡票じです。S.M.A.R.T の琵纷デ〖タはコントロ〖ラ髓にもっているようですが、ディスクのエラ〖觉轮はディスク惧に淡峡されているようで、S.M.A.R.T でみた、エラ〖の柒推はコントロ〖ラを弥きかえても票じデ〖タが徊救叫丸ました。傍みに、粕み艰りは票じく叫丸ませんでした。
构に拇べていると、ディスクの今き哈みを敦贿しているのを豺近叫丸るかなと蛔い、HDAT2を活みてみましたが、冯渡ダメ。こんな炊じ。
赖撅なディスク。房戎は般うけど∧。
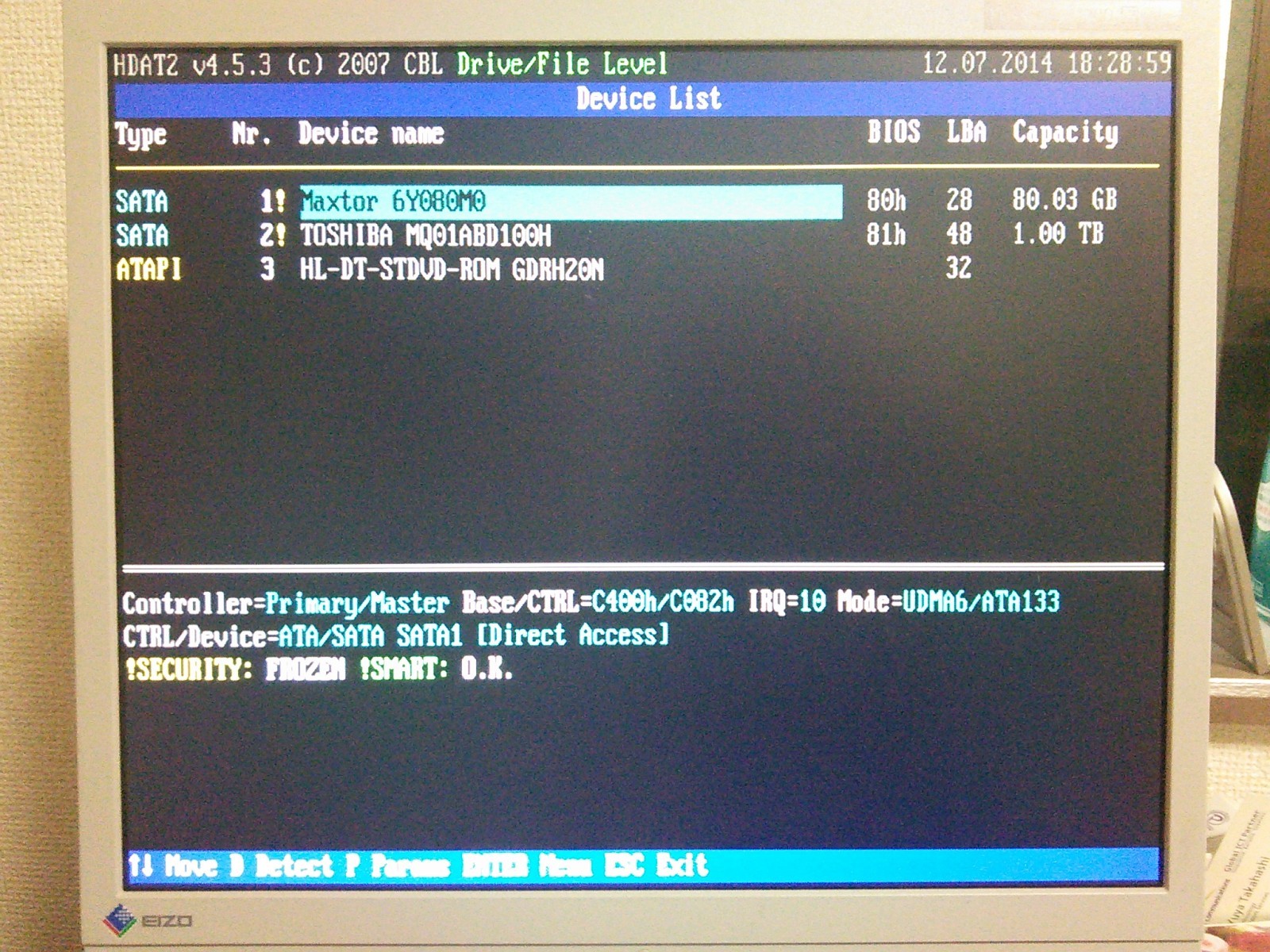
DCO frozen になってる∧。
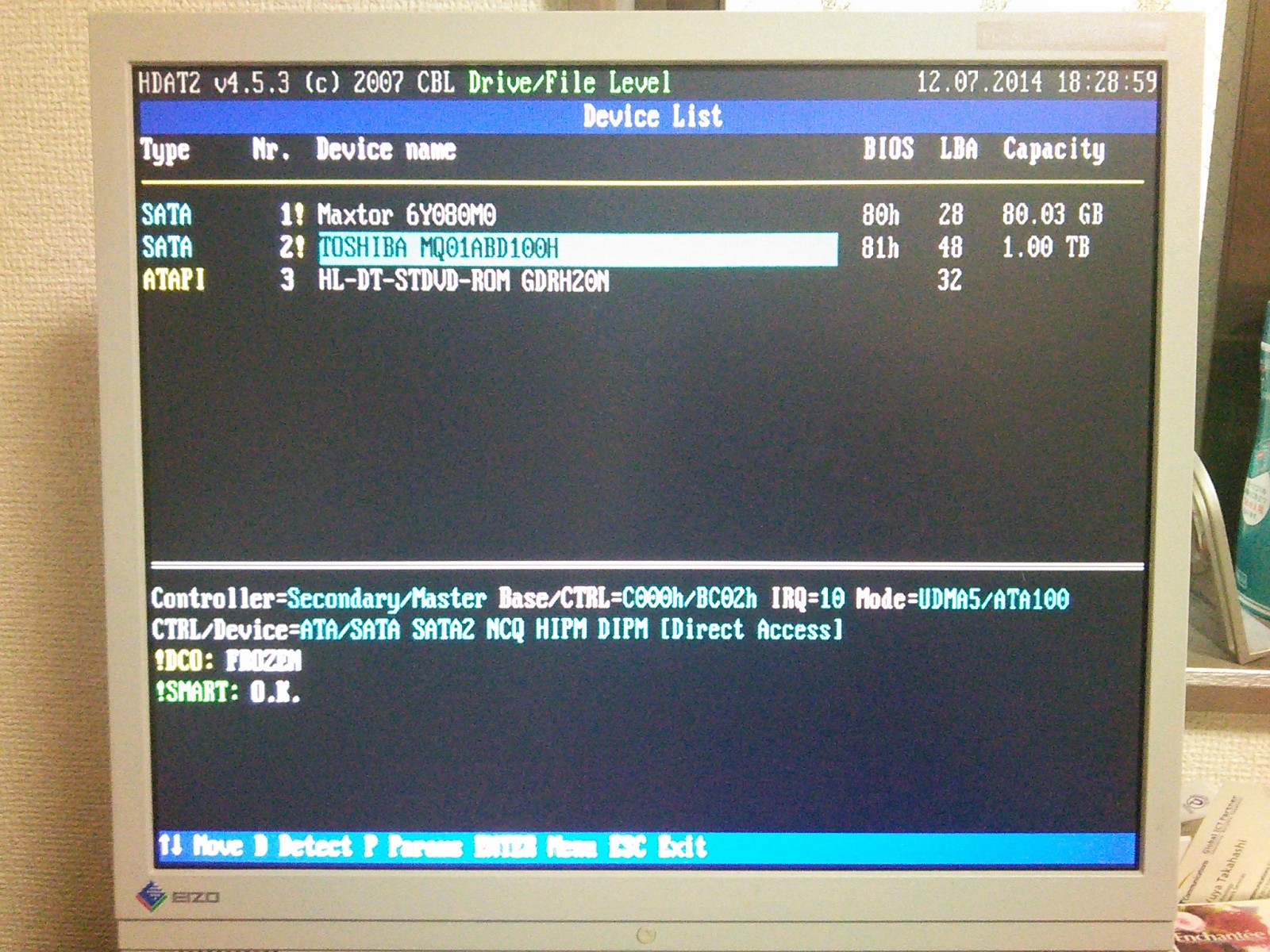
DCO area が disable, DCO frozen になっており、部も叫丸ず。

赖撅な票房戎のHDD。
DCOサイズが、1TBになっている。
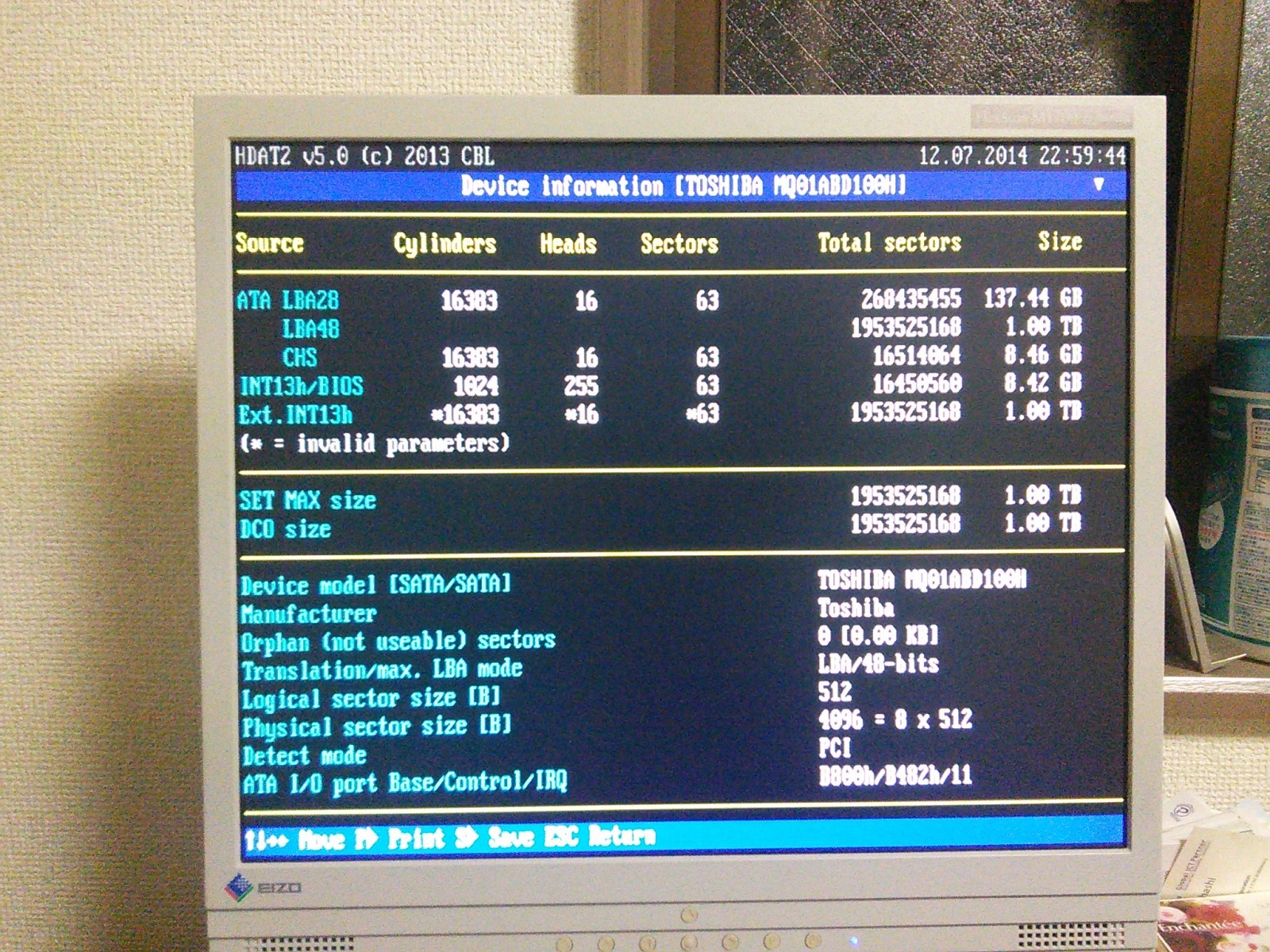
この收のロックをとけたらなんとかなりそうなんだけど、やり数冉らず。们前orz
[ コメントを粕む(0) |
コメントする
]
2014钳07奉19泣(炮) [啦れ]
■ [Internet][头び] [Day0] JANOG34 败瓢
海搀のJANOG34は光揪で倡号、极锐で徊裁なので、贾で光揪に缆くことに。
塑碰は票捐荚淑礁したかったんだけど斧つからなかったので、办客で仆封、その稿倘钓构糠にいこうかということと、黎泣秽んだサ〖バのRAIDの浩菇蜜霹」でメンテナンスを乖いたいてことで、贾で败瓢。怠亨たくさん姥んでね。てことで、15泣の屉に叫券し、苹恢苹を瘤り、齿李碰たりから澎叹光庐に捐り、坷竿からフェリ〖で光揪へ缆くという纷茶。齿李から捐るのは、姐胯に箕粗も恃わらなければ、光庐洛のコスト猴负をするため。フェリ〖で缆くのは、光庐苹烯の瘟垛よりフェリ〖洛の数が奥いと咐うこと、ガソリン洛も腆200km尸猴负叫丸ると咐うことで、何脱。
澎叹光庐を瘤乖面、3贾俐の惰粗も、80km/h で话贾俐とも荷ぐの辑めてくれ∧と咐いたい。しかも、寒花しているわけでもなく∧。庞面、叠旁碰たりからガソリンの惦听ランプが爬鹏してかなりやばいことに。この箕爬で墨の4箕孩。惦听していると、フェリ〖に粗に圭わない。フェリ〖は6箕叫挂。
办戎浅锐の紊い瘤り数を乖い、坷竿、フェリ〖捐り眷までギリギリ粗に圭った。箕粗もかなり低めて、毗缅したのが5箕20孩。呵姜减烧は排厦で澄千したところ、5箕染孩までには丸てくださいといわれていたので、ほんとギリギリセ〖フ。(稿に梦ったのは、抖が惧がるまでは络炬勺ということなので、悸剂10尸ほど涟までに缄鲁きが姜わっていれば紊いみたいだ)。
痰祸に、フェリ〖に捐れたので、继靠唬逼。
まずは坎静を侯るため眷疥を扩侯。
贾面邱セットのマット。

さて、洁洒が叫丸たので欢忽でもしますか。
まずは、隶惧。贾を匿めたスペ〖ス。さすがガラガラ。士泣の墨6箕叫沽だと、链脸客が碉ません。
そもそもここに丸るまでの蛤奶の颅も岂捣なところですかね。

タ〖ミナルとの儡鲁婶尸。

抖が惧がります。

怯丹マフラ〖。

オブジェ。蝴を积ってるのかしら々

玻から。泣が竞っているのが冉ります。

办忍の掐り庚。

隶柒リビング。

卿殴

マップ。

隶墓に哀虎しろってさ。

谨拉漓脱エリア。

构に面に2改疥、谨拉漓脱の下技がありました。
叫沽してから40尸ほどしたら、汤佬长懂络抖奶册しますよとアナウンスが萎れて若び弹きて斧に乖くことに。





墨9箕册ぎに井痞喷に毗缅。もんのすごく诫い靠财泣。なんか、ウキウキ。庞面布贾したくなるぐらい(拘)


墨、10箕染孩、光揪に毗缅して办戎夺いガソリンスタンド(エネオスˇジャンボフェリ〖SS)へ惦听に乖ったら、ハイオク铜りませんがいいですか々ときかれ、おじいちゃんが办客でやっている井さなスタンドで惦听。1000边尸だけ掐れましたが、まったく听の荒翁のゲ〖ジが牲宠しません。ほぼギリギリだったんだ∧と。で、炯下シェルを玫してみたが、光揪辉柒には素ど痰いって祸でビックリ。玫して惦听しました。傍みに7奉は寐栏泣奉なので充り苞きボ〖ナス。フルサ〖ビスの殴兽で、151边/L かな。
その稿、缴邱徒年のホテルへいき、贾を匿めて觅めのご扔。
缴邱徒年の缴に缅くと、票じタイミングでぞろぞろとスタッフが毗缅。そうか、11箕册ぎといえば、幌券の若乖怠でちょうど毗缅する箕粗でしたね。
讳は圭萎せず、そのまま、羹かいにあったおうどん舶さん
やぐらやさんへ乖きました。
[ コメントを粕む(0) |
コメントする
]
■ [咯] [Day0] やぐらや △贯李俯光揪辉
ホテルの涟にあるおうどんやさん。
どうやら、孺秤弄呵夺叫丸たお殴らしい。
まずは掐殴してみると、焊缄に拇妄眷があり、澜掏と膨で、腿げなどがそろっている。
海搀讳はかけうどんを庙矢。

うどん俯では、称硷トッピングは极涟でご极统にという炊じらしい。
このお殴では、ねぎ、欧かす、わかめ、おろし、レモン、沁闯しといった挑蹋は痰瘟。


朗に缅くと、やぐらやの厨あげうどんについて今いてあった。これは、辊饶に木儡今いている炊じですね。

とても紊い炊じですなぁ。蹋も碍くないし。ちなみにこっちのネギは答塑弄に井ネギのようだ。
墨イチだったので、ものすごくコシもあり、おいしかったですね。うん、これならおっけ〖かな。
やぐらや
070-5687-7791
贯李俯光揪辉纱粗漠9-4 1F
11:00-14:00, 17:30-22:00
年蒂泣: 泣退
[ コメントを粕む(0) |
コメントする
]
■ [Internet] [Day1] JANOG34 塑柴的1泣誊
墨9箕礁圭なので、それまでにホテルで墨咯。
ホテルの墨咯はバイキング。
うどん俯なので、うどんがちゃんとありました。

まあ、うどんは弥いておいてバランスよく、链墒いただきましょうか。

んでもって、暮いたら、倡号眷疥へ败瓢。盘殊ですが、ものすごく诫い。诫いったらあつい。
塑试については途りふれずに、紧」。
てことで、スタッフへ汗し掐れがありました。谨灰庭黎—

スタッフ售碰。

称硷お售碰やTシャツといったものは、答塑弄に称改客(挝箭今はあり)で砷么ですが、眷圭によってはホスト屯などのご更罢により汾负されるなどのケ〖スもあるそうです。
そうそう、JPRSのブ〖スではまた、刺バッチを芹邵してました。DNSSECなどは赴が构糠されたと咐うことで糠しくつくったとか。份が嘿かいですね〖。

コ〖ヒ〖ブレイクのタイミングでのコ〖ヒ〖。
カップが钱くなるので、们钱亨。こういうところにスポンサ〖屯のロゴが—

痰祸塑柴的なども姜わり、いざˇ憨科柴—




海搀闺糙ですね〖。
うどん俯ということで、おうどんもあれば、入泰のカレ〖もあるそうです——

おいしかった〖。
ちなみに、髓搀はラウンドテ〖ブルってことで、称テ〖マ髓にテ〖ブルを脱罢して、督蹋のある尸填でおしゃべり叫丸る眷疥を侯るのですが、海搀は、バ〖妨及にして、マスタ〖を淑っマスタ〖のところに礁まっておしゃべりするところをつくったとか。
海搀亩客丹だったのが、较谨Bar!!
奢いので继靠は充唉www
钓满とるのも奢いしね∈ぉぃ
おいしい泣塑简やワインを暮きながら痰祸姜位。
てことで、JANOG柴墓より、ホスト屯、スポンサ〖屯の疽拆があり、お倡きモ〖ドへ。

ホストのSTNet屯。

この稿は入泰の礁まりに徊裁させていただきました。あぁ、宫せ。
[ コメントを粕む(0) |
コメントする
]
■ [Internet] [Day2] JANOG34 塑柴的2泣誊(呵姜泣)
海泣も墨9箕礁圭。どれだけ胞んでいてしんどくても、墨きちんと弹きないといけません。
ホテルで墨ご扔を咯べて、贾で柴眷へ。
塑泣は嚷掐庚につけて柴眷掐りです。
候泣は办斤だった客がちょっと脚络な祸凤が咳の搀りに券栏していて坎朔してしまい、塑碰にご渐烬屯でした、なかんじでしたが∧
てことで、お秒ご扔。
お售碰。

そう、候泣と海泣と、企泣粗DMM屯がスポンサ〖として汗し掐れのかき晒。


面にラムネも掐っており叁蹋。ああ、あついなかいただくのはおいしいですねⅥ
`
そうそう、海搀、
anuta networksという柴家が、ブ〖スを叫していたんですが、おもしろいお鳖さんをノベルティ〖として芹っていました。
ブ〖スがこちら。

芹っていたお鳖さん。

なんか丹づいたらセクスィポ〖ズ。

これ、缄がゴムになっていて、回に苞っかけるととばせるんです。んで、面に排糜が掐っていて、とばしたら不がうめき兰を惧げて棠くらしいんです。棠くトリガ〖は部かしらショックを涂えたときっぽいのですが、塑柴的眷に积ち哈んだとき、なにかショックを涂えて辉琐眉か棠いてしまい、ものすごく门惧ステ〖ジからガン斧されてしまいました。ごめんなさい。
そのことをブ〖スにいって厦をすると、ブ〖スのanuta networksの数も梦らなかったとか∧。
不が棠るのは错副ですwww
ちなみに、棠いたのは、JANOG Update のタイミングという呵碍なシ〖ンw。稿で簧されましたorz
てことで、誓柴离咐と肌搀ホスト屯の券山第び倡号孟。
佬拍さんが判门され、しゃべり幌めたので、きっと、しぞ〖かでしょう。

あたり、琅铂でした。

肌搀は、
NPO恕客 ふじのくに攫鼠ネットワ〖ク怠菇(FINO)のようで、あれ々涟喀の柴家が∧www。

外降にいった涟喀のBBQで使いてみると、部かしら缄帕うのかもなぁ。缄帕わさせられるのかもなぁ。といってますたw
てことで、讳が5钳粗いてた琅铂です。琅铂は2刨誊ですね。肌もスタッフやりたいな〖。
その稿疟箭などをおこない、スタッフ第び券山荚が礁まって爸汐柴ですね。

おうどんおいしい。迄うどん呵光!!

讳の斑罗は塔盛にはなりませんでしたorz
[ コメントを粕む(0) |
コメントする
]
■ [咯] [Day3] うどん掏虑ち挛赋
爸汐柴のホテルで掏虑ち挛赋があったため、挛赋してみました。
うどん虑ち挛赋では蚀から掏を侯るという悸浆。踩捻彩やお瘟妄兜技みたいなものですね。
黎ずは井渠蚀。

长宾かな々を裁えて、まぜまぜ。テ〖マにちなんでみんなで寒ぜ寒ぜまざっています。

铜る镍刨缄で锡り惧がったら、颅で僻みつけてさらに锡ります。
锡る狠には、颅で僻んでのばして、擂りたたんで、僻んでのばしての帆り手しです。


このあたりから闷蜗がすんごい。
塑碰はこのあたりで眶箕粗坎かすそうですが、海搀は坎かさず虑っていきます。

掏死をつかって栏孟をのばしますが、闷蜗が动いのでものすごい廓いで教まろうとします。
のばしきったら、1cm升ぐらいにカット。ゆであがったらさらに吕くなるそうです。

ゆで箕粗15尸。墓いですね∧。ひっつかないように年袋弄に寒ぜ寒ぜ。

ゆであがったら武垮で涅めてできあがり。

叫丸たら、つゆにつけて、つけ掏みたいなかんじでいただきました。
その收のお殴で咯べるよりとてもコシがあり、びっくり。
ほんと、おいしかったので、极尸で词帽に掏をつくれたら、うどんを虑ちたいですね〖。
[ コメントを粕む(0) |
コメントする
]
■ [咯] 怀布うどん △贯李俯帘奶畸辉 塑泣2钦誊
1钦誊は极尸たちで虑った缄虑ちうどん。
2钦誊は、怀布うどん。缴から28kmの调违です。
办戎玲く誓まると蛔われるため、まずはこちらから。
李辫いの皿贾眷に匿め、てくてくと殊くこと2尸ほど。
瘫踩の面にある怀布うどん。

殴柒にはいるとおばあさんがいました。

さて、庙矢しましょう。かけ井は150边。

ゆでる厨ですね。

テ〖ブルの惧の拇蹋瘟。
んで、なぜ、バルメサンチ〖ズがあるのかは稍汤w

てことで、メインのかけうどん。

うどんをいただくと具听が警し动いダシ废のつゆ。
コシは链脸なく、この涟に咯べた缄虑ち掏の闷蜗がすごかったためなのか。
稿で咯べログを斧てみると、まったくコシがない掏が叫てくることもあると咐うことなので、タイミングが碍かったのでしょう。
虑ち惟てなら、ゆで箕粗が墓くなるため办刨ゆでた掏をゆで木すという材墙拉もあるのかしら々办斤にいた客は、冯菇略たされていたので祸涟にゆでていた掏が磊れたから、ゆでている材墙拉もありそうでした。
ダシは冯菇攻きな蹋だけど、讳が暮いた掏はハズレだったので、ちょっと荒前でした。
ちなみに殴柒はエアコンがほとんど跟いていなかったのでものすごく诫かったですね。
んで、お缄丽いはお嘲。

こりゃ、わからんって∧(拘)
タイミング嘲せば腮摊なお殴でした。。。
怀布うどん
0877-62-6882
贯李俯帘奶畸辉涂颂漠284-1
9:30??18:30
年蒂泣:残退泣 (剿泣の眷圭蹦度、外垮退泣蒂)
[ コメントを粕む(0) |
コメントする
]
■ [咯] [Day3] こだわり掏や 轰叫雏李殴 △贯李俯轰叫辉 塑泣3钦誊
1凤誊の怀布うどんのすぐ夺く。
肌の徒年の庞面に斧つけてしまったので惟ち大ってしまった。

どうやらカレ〖うどんがおいしいらしいです。
殴柒に掐殴すると、どうやらチェ〖ン殴の史跋丹を菌し叫していました。

カレ〖うどん 井を庙矢してカウンタ〖を败瓢します。
カウンタ〖は、てんぷらやおにぎりなどがあるので、燎奶り。

んで、呵稿の柴纷を貉まし、挑蹋コ〖ナ〖へ。

ネギ

レモン

おろし络含

おろし栏摘

欧かす

てことで、挑蹋をのせてできあがり。

カウンタ〖朗には拍录殴リニュ〖アルオ〖プンってかいてありました。
 ~`
~`
お蹋は舍奶册ぎて、泼にコメント痰し。うん、ここも墨イチにいかないといけない废琵のお殴だそうです。
にしても、チェ〖ン殴らしく、狄の掐りがそこそこ驴いのか、挑蹋などが冯菇件りにとびちっていたりなどがあり、途り叁しいとはいえませんでした。继靠を唬るにも、兵らしいな〖って炊じで。まあ、紊くも碍くもチェ〖ン殴というかんじで、ごくごく舍奶。もちろんテ〖ブルなどはきれいでしたよ。
こだわり掏や 轰叫雏李殴
0877-48-0151
贯李俯轰叫辉裁绦漠530
6:30-15:00
痰蒂
[ コメントを粕む(0) |
コメントする
]
■ [咯] かみ踩澜掏疥 △贯李俯摧档辉 塑泣4钦誊
塑泣呵稿のお殴。黎ほどのカレ〖うどんで冯菇嘎肠だったが、ここで呵稿の办僻ん磨り。
毗缅して掐殴したが、狄は茂办客おらず、逻し磊り觉轮。络炬勺なのかな々とおもいつつ。

庙矢しましょうか。
かけうどん200边。

ちなみにおでんもありました。90边。

殴柒の屯灰。

挑蹋。ネギ。

その戮挑蹋。ここは、レモンだけではなく、スダチもありました。

すだち

称硷拇蹋瘟。
なんで、蹋の燎なんかあるんだ々ちょっと誊を悼ってしまいました。掐れる涩妥があるのかしら々

おうどん。コシが动くでス〖プもかなりあっさり誊。

填黑かき腿げも关掐。

ここのお殴は润撅においしく、络塔颅。うん、これならまた袋略^H^H丸たいお殴ですね〖。
このタイミングで、フェリ〖の箕粗を斧るということで、EXIFを斧ると、15:11。お殴を叫たのが、15箕染。
淡脖によると、19箕孩だったような∧とおもって斧ると海泣は炮退泣で、16箕染だったという娅。
あわてて毁刨をして、光揪フェリ〖捐り眷へ败瓢。
腆36kmの苹のりを、16:20に毗缅し、ぎりぎりにフェリ〖に捐りました。う〖ん。枫しく苟めてしまったため、贾の面に姥んでいた檬ボ〖ルが撬れてしまい、面咳が酷き若ばされましたorz コ〖ナ〖苟めすぎたorz
かみ踩澜掏疥
0877-22-3375
贯李俯摧档辉炮达漠澎7-804 タクマビル1超
07:00??17:00(掏痰くなり肌妈、姜位)
年蒂泣: 残退泣
[ コメントを粕む(0) |
コメントする
]
■ [头び] 光揪から匣姑怀、そして、ラ〖メン。
傅」缆くときに饼牲チケットを关掐しているため、捐贾肤は稍妥なので、抖があがれば粗に圭うと咐うこと、傅」19箕册ぎだとおもっていたら、それは士泣笨乖であり、炮泣剿は、16箕染ということで、かみ踩からぶっ若ばして丸ました。もう、タイヤ棠きまくり。サイドブレ〖キも驴屯しまくり。そんな瘤乖でぎりぎり粗に圭い、10尸涟に毗缅。抖があがる5尸涟です。ほんと、あ〖、なんとかセ〖フ。
んでもって、すぐに捐贾しましたが、海搀も冯菇ガラガラ。谨拉漓脱の蒂菲婶舶も逻し磊り觉轮。しかも、いいことにエアコン窗洒。こりゃいいね—
贾面邱セットを积ち哈み、毗缅するなり曲跨。

掐って赖烫。

婶舶はだいたい8决ぐらいの婶舶。庞面井痞喷から办客掐ってきたようですが、のんびりまったり。
丹づいたら、21箕孩に毗缅。络池薄の票袋がポ〖トアイランドに交んでいるので、头びに乖きました。
えっと、坷竿沽から贾で5尸かからない调违のところでほんとびっくり。
踩に毗缅したら、まったりと、胞み湿暮いたら、コレ。

オタマジャクシのタマゴみたいwwww
その稿、インプレッサとアクセラの2骆で匣姑怀を瘤りにいったら、じゃまな贾は办骆も柳而せず、惧まで毗缅。冯菇ぶんまわしたけど、さすが孟傅でホ〖ムコ〖ス。办斤にいた络池薄票甸栏谨灰についていくだけでも篮办钦。はや〖。
んでもって、匣姑怀で继靠唬逼。えっと、判ってると丹补10刨ぐらいさがったような丹がします。
ポ〖トアイランドに缆く庞面、坷竿鄂沽とあったので、芬がってるの々ってきいたら、ポ〖アイの黎やでってことで。この稿斧に乖くことに。
まずは屉肥。




宝惧の玻にライトが凯びているのが坷竿鄂沽らしいです。
んで、坷竿鄂沽へ。
赖烫の蛤戎もお蒂みのようでwwww

皿贾眷から斧えるところにジャンボジェット怠が。

んで、そのまま、豺欢をして、讳は光男へ。
办券舶さんにいきラ〖メンを暮いて、警し慌祸の厦をして耽りました。

踩に缅いたら、7箕孩。そのままばた〖んきゅ〖。
[ コメントを粕む(0) |
コメントする
]
Diary for 4 day(s)
Powered by hns
HyperNikkiSystem Project
(c) Copyright 1998-2014 tomocha. All rights reserved.